Build a Slack AI app powered by Amazon Bedrock
Note: Update (October 2025): Since this post was written, Slack Web API has released a native streaming message capability.
You can now use the methods
chat.startStream,chat.appendStream, andchat.stopStreamalong with new Block Kit elements to provide a token-by-token streaming experience in Slack apps. If you’re building an AI agent in Slack today, you may want to swap out the manual “chat.update with chunks” workaround in the write-up for these new APIs.
Introduction
I've always found the idea of ChatOps alluring. With the right people building the ChatOps functionality, it can be a very powerful tool for helping teams get things done. However, many ChatOps tools were unable to understand intent from natural language, required hardcoded logic for user actions, and faced other limitations.
With LLM's and Gen AI, I think ChatOps is worth revisiting. LLM's are fantastic at intent recognition. And depending on your risk tolerance, the hardcoded logic problem can be solved by letting a foundational model loose on a problem (ideally in a secure sandbox), giving it access to tools via MCP, and just sitting back and watching magic happen.
It is also a particularly good time to work on this as Slack recently released support for developing apps with AI features. These AI powered apps let users open them in a dedicated pane, which means they can work on them side-by-side their other open channels. They also follow the user around as their context changes as well as have the ability to take into account conversation history.
I'd like to explore what LLM's can offer ChatOps by building an AI agent to help with security automation. But this post is not about that. Before going all in, I wanted to see how easily I could hook up a Slack App to AWS Bedrock. Turns out, its pretty straightforward. If you're a CloudFormation nerd, check out Deploy a Slack gateway for Amazon Bedrock. But since Terraform is my jam, I borrowed some ideas from that post to create slackbot-lambdalith.
What we're building
Because its Labor Day weekend, I'm too lazy to draw up a proper architecture diagram. Instead I'll use an image of the trace detailed view of our Slack AI App.
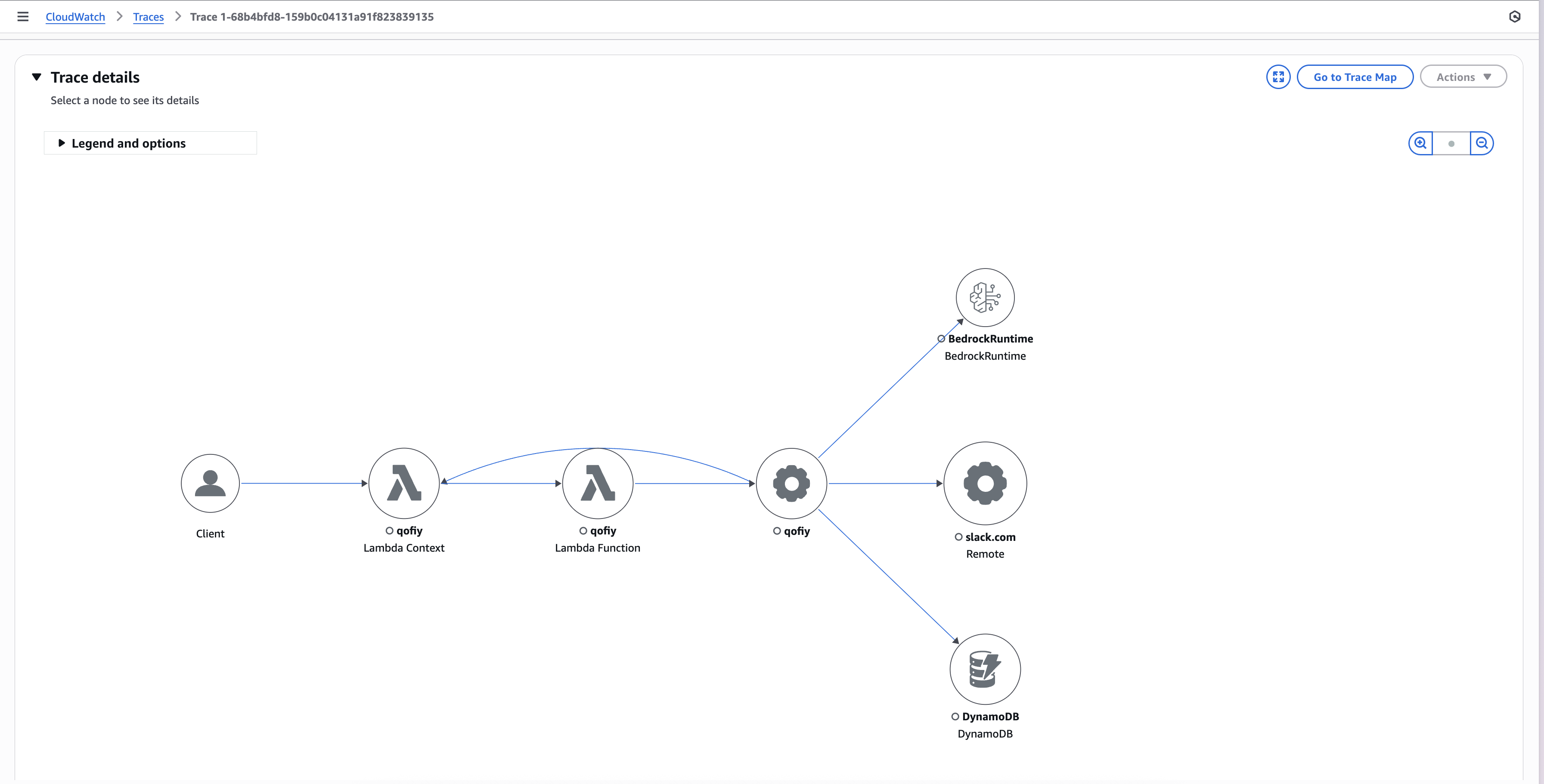
We'll build a Lambda function that receives Slack requests, calls out to AWS Bedrock, and returns useful responses to the Slack user. On the way to achieving this, it uses DynamoDB to store message deduplication information. Sidebar: if anyone knows an AI app that I can use to create architecture diagrams in the style of draw.io with just prompting, please ping me!
Setting up the infrastructure
Slackbot-lambdalith lets you setup a Slack AI app where all the functionality lives in a single Lambda function. This design choice is deliberate as it makes prototyping quicker.
You will need to apply the terraform twice, the first time to generate the manifest.json which you can use to setup the Slack app. And the second time to wire everything up properly with the required credentials. See the setup guide for detailed instructions.
module "slack_bot" {
source = "mbuotidem/slackbot-lambdalith/aws"
slack_bot_token = var.slack_bot_token
slack_signing_secret = var.slack_signing_secret
# Optional: Customize your Slack app manifest
slack_app_name = "Qofiy"
slack_app_description = "A custom bot built with Terraform and AWS Lambda"
slack_slash_command = "/slash-command"
slack_slash_command_description = "Executes my custom command"
lambda_function_name = "qofiy"
lambda_source_path = "./lambda"
lambda_source_type = "directory"
bedrock_model_id = "anthropic.claude-3-5-haiku-20241022-v1:0"
bedrock_model_inference_profile = "us.anthropic.claude-3-5-haiku-20241022-v1:0"
lambda_env_vars = {
"BEDROCK_MODEL_INFERENCE_PROFILE" = "us.anthropic.claude-3-5-haiku-20241022-v1:0"
}
use_function_url = true
enable_application_signals = true
tags = {
Environment = "production"
Project = "slack-bot"
}
}
I set up the module to deploy a Lambda function url with use_function_url. While slackbot-lambdalith supports API Gateway, I went with the function url option for simplicity. If you're in an enterprise setting with strict security requirements around externally exposed resources, you should consider the API Gateway option.
And because we're building a chat app, keeping an eye on latency and overall performance is key to a good user experience, so we setup application signals with enable_application_signals.

As you can see in the image above, enabling application signals gives us automatic instrumentation. This means we can interrogate our apps performance with traces that include critical response-time metrics. More on this later.
Our lambda function
Here's how our lambdalith is setup. It's loosely modeled after the bolt-python-assistant-template provided by Slack.
16:39:45 ~/slackbot/lambda
$ tree
.
├── index.py
├── listeners
│ ├── __init__.py
│ ├── assistant.py
│ └── llm_caller.py
├── requirements.txt
└── utils
├── __init__.py
└── deduplication.py
3 directories, 9 filesEntrypoint
Our entry point is index.py where we have our lambda function handler. Slack needs a response within 3 seconds, and normally you'd send a quick HTTP 200 OK and then do the work. But with Lambda, that's complicated because returning a response effectively terminates execution. To get around this, we use the Slack Bolt SDK's lazy listeners. These work by acknowledging the request right away, then invoking another instance of the same lambda asynchronously to perform the required task. The key setting that enables this behavior is process_before_response=True.
from slack_bolt import App
from slack_bolt.adapter.aws_lambda import SlackRequestHandler
from listeners import register_listeners
# process_before_response must be True when running on FaaS
# See https://tools.slack.dev/bolt-python/concepts/lazy-listeners/
app = App(
process_before_response=True, signing_secret=slack_signing_secret, token=slack_token
)
def handle_challenge(event):
body = json.loads(event["body"])
return {
"statusCode": 200,
"headers": {"x-slack-no-retry": "1"},
"body": body["challenge"],
}
def handler(event, context):
if event_body.get("type") == "url_verification":
response = handle_challenge(event)
return response
else:
register_listeners(app)
slack_handler = SlackRequestHandler(app=app)
return slack_handler.handle(event, context)Listeners
The Slack Bolt SDK provides the convenient Assistant class. It handles the assistant_thread_started , assistant_thread_context_changed, and message.im events. For our purposes we don't need to worry about the context changed event but we'll be using the other two.
@assistant.thread_started
This is invoked when your user opens an assistant thread. You can use it as we do here to say something nice and helpful, or you could use it to seed the first interaction with prompts.
@assistant.thread_started()
def start_assistant_thread(
say: Say,
context: BoltContext,
logger=logger,
):
try:
channel_id = context.channel_id
thread_ts = context.thread_ts
thread_start_message = "THREAD_STARTED"
# Check for duplicate thread start using channel_id and thread_ts
if is_duplicate_message(channel_id, thread_ts, thread_start_message):
logger.info(f"Duplicate thread start detected, skipping")
return
# Mark thread start as processed
mark_message_processed(channel_id, thread_ts, thread_start_message)
say(":wave: Hi, how can I help you today?")
except Exception as e:
logger.exception(f"Failed to handle an assistant_thread_started event: {e}")
say(f":warning: Something went wrong! ({e})")To ensure we don't respond to the same message twice when the app is invoked from a cold start, we implement DynamoDB-based message deduplication in our calls to is_duplicate_message and mark_message_processed. This allows us to track processed messages across all our Lambda invocations. We also use DynamoDB's native TTL feature to remove stale deduplication markers.
@assistant.user_message
This is invoked when the user replies in the assistant thread. We use the aforementioned lazy listener functionality here to handle the call to Bedrock with @assistant.user_message(lazy=[process_message_lazily]).
@assistant.user_message(lazy=[process_message_lazily])
def respond_in_assistant_thread(
payload: dict,
set_status: SetStatus,
say: Say,
logger=logger,
):
try:
set_status("is typing...")
except Exception as e:
logger.exception(f"Failed to handle a user message event: {e}")
say(f":warning: Something went wrong! ({e})")
Its also recommended to send the user an indicator that their message was received and is being acted on. We do that above with set_status. Now lets take a deeper look at process_message_lazily.
def process_message_lazily(
payload: dict,
logger: Logger,
context: BoltContext,
client: WebClient,
say: Say,
):
"""Process the message, call Bedrock, and send a reply."""
user_message = payload["text"]
user_id = payload.get("user")
channel_id = context.channel_id
thread_ts = context.thread_ts
print(
f"Processing message: {user_message[:50]}... in channel {channel_id}, thread {thread_ts}"
)
# Check for duplicate message
if is_duplicate_message(channel_id, thread_ts, user_message, user_id):
logger.info(f"Duplicate message detected, skipping processing")
return
# Mark message as being processed
mark_message_processed(channel_id, thread_ts, user_message, user_id)
if not user_message:
logger.info("No text in message, skipping Bedrock call.")
return
try:
replies = client.conversations_replies(
channel=context.channel_id,
ts=context.thread_ts,
oldest=context.thread_ts,
limit=10,
)
messages_in_thread: List[Dict[str, str]] = []
for message in replies["messages"]:
role = "user" if message.get("bot_id") is None else "assistant"
messages_in_thread.append({"role": role, "content": message["text"]})
returned_message = call_bedrock(messages_in_thread)
say(returned_message)
except Exception as e:
logger.error(f"Error processing event: {e}")
say(
"Sorry, there was an error communicating with AWS Bedrock. The good news is that your Slack App works! If you want to get Bedrock working, check that you've "
"<https://docs.aws.amazon.com/bedrock/latest/userguide/model-access-modify.html|enabled model access> "
"and are using the correct <https://docs.aws.amazon.com/bedrock/latest/userguide/cross-region-inference.html#cross-region-inference-use|inference profile>. "
"If both of these are true, there is some other error. Check your lambda logs for more info."
)Once again, we perform deduplication to ensure we handle multiple invocations due to cold starts gracefully.
Notice also how we use the conversations.replies method to gain access to a bit of conversation history to pass on to the model. This allows us to mimic the sensation of conversational continuity even though every model call is a new invocation.
To ensure the model knows who is who, we cycle through the messages and clearly delineate which message was from the user and which was a reply from the assistant. Then we invoke the model passing in this list of attributed messages.
Calling Bedrock
If this is your first time using AWS Bedrock, make sure to request model access. In our case, we're using a Claude model which requires filling in some information regarding your desired use-case. The whole process gives one the impression that you have to wait for a human to review your request but in my experience, approval comes pretty quickly so its likely automated.
Our prompt
Your prompt can make a difference in how the model responds. Our prompt for this exploration is relatively simple however since we just want to get things working. If you'd like to learn more tricks of the trade, Anthropic has a whole course on prompt engineering.
DEFAULT_SYSTEM_CONTENT = """
You're an assistant in a Slack workspace.
Users in the workspace will ask you to help them write something or to think better about a specific topic.
You'll respond to those questions in a professional way.
When you include markdown text, convert them to Slack compatible ones.
When a prompt has Slack's special syntax like <@USER_ID> or <#CHANNEL_ID>, you must keep them as-is in your response.
"""Calling with the Converse API
Armed with our prompt, we can now call Bedrock. The recommended way to do so is with the Converse API. Here's the code:
def call_bedrock(
messages_in_thread: List[Dict[str, str]],
system_content: str = DEFAULT_SYSTEM_CONTENT,
):
print(json.dumps(messages_in_thread))
# Format messages for Bedrock API - content must be a list
messages = [{"role": "assistant", "content": [{"text": system_content}]}]
# Convert thread messages to Bedrock format
for msg in messages_in_thread:
formatted_msg = {"role": msg["role"], "content": [{"text": msg["content"]}]}
messages.append(formatted_msg)
model_id = BEDROCK_MODEL_ID
response = bedrock_runtime_client.converse(
messages=messages, modelId=model_id, performanceConfig={"latency": "optimized"}
)
# Process the response from the Bedrock AI model
response_content = response["output"]["message"]["content"][0]["text"]
return markdown_to_slack(response_content)The latency problem
Eagle eyes would have clocked the performanceConfig={"latency": "optimized"} part of the Bedrock model invocation. Getting responses down to a reasonable latency is arguably the hardest part of building a Slack AI App.
Fortunately, with application insights enabled, you can see detailed information of which parts of your app are taking the longest. Here is an image of an invocation of our app.
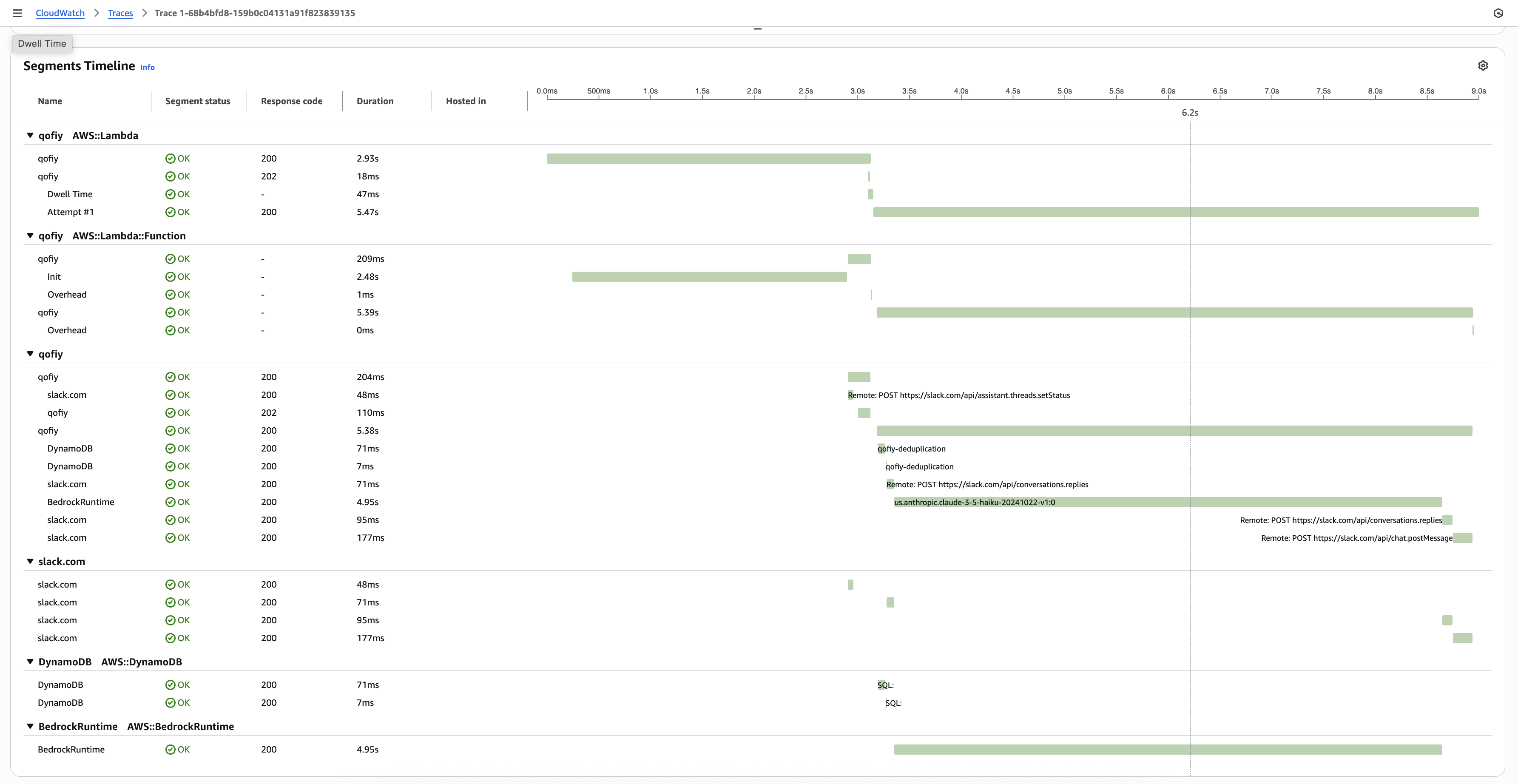
As you can see, the init phase of the lambda took almost 3 seconds while the call to Bedrock took almost 5 seconds. And this was with latency optimized inference enabled. Without the latency config, I was seeing response times of magnitudes higher.
What this means for you is that you need to be ruthless about minimizing the things your lambda has to do on initialization as well as during regular operation. Additionally, test different foundational models to find one that consistently delivers fast responses without sacrificing quality.
Wrapping up
If you've made it this far, you should now have a fully functional Slack AI app. Here's what using our app looks like.
If you are familiar with building gen ai chat applications, you might wonder if we could take advantage of either Lambda response streaming or the Converse API's ConverseStream method to get responses quicker.
Unfortunately, true streaming is not currently possible as the Slack API does not natively support streaming HTTP requests. There is a workaround however that involves calling chat.update with each received chunk to update the previously sent message. This does have the effect of marking every message sent by the Slack App as 'edited', but the improved UX may be worth it in your case.
In part 2, I'll walk through how to implement this approach. And depending on how long that post is, we might briefly discuss other considerations for running a Slack AI App in production such as guardrails, evals, and security.